Deleted-Record Recovery — Measured Capability¶
What sqlite_forensic::carve_all_deleted_records actually recovers, and how it
compares head-to-head against undark, fqlite, bring2lite, and DC3's
sqlite_dissect — every tool scored
against the same independent third-party ground truth: the SQLite Forensic
Corpus (Nemetz, Schmitt & Freiling, DFRWS-EU 2018, CC0), whose authors shipped,
per database, an .xml answer key tagging every deleted row with its full
content.
Both matrices below are harness-computed, not hand-written: the single-tool
matrix by forensic/tests/nemetz_metrics.rs and the head-to-head (up to five
tools — ours, undark, fqlite, bring2lite, sqlite_dissect) by
forensic/tests/nemetz_tool_comparison.rs (run either with --nocapture to
regenerate its table). Corpus and oracle provenance are in
corpus-catalog.md and validation.md.
For the false-positive angle — our 0-FP discipline measured against
bring2liteon the 2025 SQLite-recovery survey's scenarios (identical bytes), with the survey's three-technique framework — seecompetitive-landscape.md.The matrices below score freed-space deleted-record carving on Nemetz. Other recovery surfaces are validated separately in
validation.md: freeblock-clobbered 2-byte-rowid and coalesced rows (the general freeblock-reconstruction improvement), dropped table schema recovery, the rollback-journal/WAL substrate, the real-case NIST Data Leakagesnapshot.db(both deletedcloud_entryrecords, incl. the freeblock-clobbered one), NIST SFT-05 native-type/BLOB reading, and the independentsqlite-unhideanswer-keyed corpus. Those carver improvements left the Nemetz numbers below unchanged (0C cross-tool recall 0.833).
Executive summary¶
- Freeblock-aware reconstruction leads in-page recall, at the highest precision
of any tool. On the in-page-deletion category
0C, our carver recovers 70 of the 84 recoverable deleted rows (recall 0.833), ahead of fqlite 67 (0.798) and undark 14 (0.167). We do it at precision 1.000 (0 phantoms) versus fqlite's 0.798 (17 phantoms) — higher recall AND zero false rows. - Our carver still never re-surfaces a live row. Across the in-scope corpus
it emits 0 live-re-reads — the structural 0-false-positive guarantee held
through the change. fqlite also holds 0; undark does not — on
0Dit re-reads 56 live rows as deleted (precision 0.091) and on0E27 (precision 0.333). - On
0D(deleted then overwritten), ours and fqlite both recover every row whose full identity still survives — substrate recall 1.000, precision 1.000 — against an honest contiguous full-row denominator of 19 (the other ~26 of 45 deleted rows were destroyed by later overwrites; end-to-end recall is 0.422). - Overflow (
0E) is now partially recovered, still a limited capability. Chain-aware overflow recovery reassembles a deleted row whose payload spilled onto a freed overflow-page chain when every chain page survives as a freelist leaf (content-preserving). Of the 12 deleted0Erows, 3 survive in-page and contiguously and 1 spilled chain (0E-01Ella, chain page 13 a freelist leaf) reassembles byte-perfect — substrateDrec = 4, ours recovers all 4 (substrate recall 1.000, precision 1.000). The other spilled chain (0E-01Matteo, chain page 5 reallocated as the freelist trunk) was destroyed: it is correctly NOT recovered as a full row and surfaces only as a Tier-2 fragment (id,namefrom its intact local prefix). End-to-end0Erecall is 0.333 — most deleted0Ebodies were genuinely overwritten, which no carver can undo. On0Cours leads on recall as well as precision. - The mechanism: when SQLite frees an in-page cell it overwrites the cell's
first four bytes (payload-length + rowid varints, the record
header_len, and the leading serial type) with the freeblock header.reconstruct_freeblock_recordsrebuilds each freed cell from its surviving serial-type tail plus a header template derived from a live cell on the same page; the destroyed rowid is surfaced as unknown (0), never invented. See "Freeblock reconstruction". - A separate Tier-2 fragment surface salvages partial rows where a full identity
is destroyed but a distinctive cell survives. It is shown by default but kept
structurally separate from the full-row tier (its own labelled section /
kindcolumn), because it has an expected non-zero false-positive rate;carve --no-fragmentssuppresses it for a pure high-precision full-row run. See "Two-tier recovery". - Two recall denominators are reported because they answer different questions — substrate-limited (carver capability) and end-to-end (examiner usefulness).
- These are honest measurements of each tool against this corpus, not a verdict that any tool is "best": stated plainly below.
- Scope. This page measures free-space carving against the Nemetz corpus
(which ships no WAL/journal fixtures). The other recovery substrates —
uncheckpointed WAL frames/snapshots and the rollback journal (the last
transaction's deletes + edits) — are validated separately against NIST CFReDS
ground truth (SFT-03: WAL, and PERSIST journal 100/100); see
validation.md.
Head-to-head — ours vs undark vs fqlite vs bring2lite vs sqlite_dissect (computed)¶
Every tool's recovered rows are matched against the same answer key by a
format-stable (col1, col2) identity (the two integer/text columns at positions
1 and 2 — name/surname for the text tables, the two non-id integer columns for
the integer tables). These columns uniquely identify every deleted row in every
0C/0D/0E database and are byte-stable across tools; the floating-point columns are
excluded from the key because the three tools render reals at different
precision (ours 5 dp, undark 6 dp, fqlite 8 dp), which would penalise float
formatting rather than recovery. Two databases — 0C-06 and 0C-07 —
carry FLOAT values at positions 1 and 2, so no format-stable cross-tool key
exists for them; they are excluded from this table (our own single-tool matrix
still scores them, rounding reals symmetrically). Categories 0A/0B
(dropped/overwritten tables — no live-vs-deleted anchor) carry no clean
row-level deleted set and are out of scope for this cross-tool recall table.
Full-corpus scope (v2.0). The vendored corpus is now the full 141-DB Nemetz v2.0 (23 categories). This head-to-head table stays scoped to
0C/0D/0Ewhere the tools have oracle output and a format-stable key exists; the numbers above are unchanged. The newly-vendored deleted-ground-truth categories07(fragmented contents) and the anti-forensic17(manipulated freeblocks) /18(manipulated freelist trunks) are scored by our single-tool matrix (nemetz_metrics.rs):07recovers its lone deleted row's substrate;17/18have a near-zero substrate denominator (the manipulation destroys contiguous identity) and the carver recovers 0 full rows there while re-surfacing 0 live rows. Every false positive across the full 141-DB corpus is content-free — 39 benign phantoms + 5 recoveredsqlite_masterschema rows, 0 real-content precision regressions (gated bynemetz_metrics::phantom_fp_ceiling). All 141 DBs additionally pass the panic-freenemetz_robustness.rspipeline harness.
Ddel = rows deleted; Drec = of those, the recoverable substrate — rows whose
scored identity still physically survives in the file; live = live rows wrongly
recovered as deleted (must be 0); recall denominators as defined under
"How the matrix is computed".
The substrate denominator is the honest contiguous full-row-identity count, decided per record by body size (not by category): a deleted row is recoverable only when its whole record body — every column's bytes, in column order — survives as one contiguous run, mirroring the recall matcher's full-row key. Under this rule:
0Ddrops from 36 to 19 — overwrites genuinely destroyed roughly 26 of the 45 deleted rows; the substrate is small for that reason, not because the harness is lenient.0Esubstrate is 4. Most0Edeleted bodies are large-but-in-page and survive as a single contiguous run (tested honestly). The records whose payload exceeds the in-page limit (usable − 35) spill to an overflow-page chain (SQLite file format, "Cell payload overflow pages"); chain-aware recovery now counts such a row as recoverable when its chain is followable through freelist leaves to a byte-exact reassembly. One of the two0Espilled chains qualifies (Ella, chain page 13 a leaf); the other (Matteo, chain page 5 the freelist trunk) was overwritten and stays excluded.0C(no overwrites) stays fully recoverable (101/101 on the single-tool matrix).
| cat | tool | Ddel | Drec | TP | FP | FN | live | recall (substrate) | recall (e2e) | precision |
|---|---|---|---|---|---|---|---|---|---|---|
| 0C | ours | 84 | 84 | 70 | 0 | 14 | 0 | 0.833 | 0.833 | 1.000 |
| 0C | undark | 84 | 84 | 14 | 10 | 70 | 4 | 0.167 | 0.167 | 0.583 |
| 0C | fqlite | 84 | 84 | 67 | 17 | 17 | 0 | 0.798 | 0.798 | 0.798 |
| 0C | bring2lite | 84 | 84 | 40 | 0 | 44 | 0 | 0.476 | 0.476 | 1.000 |
| 0C | sqlite_dissect | 84 | 84 | 51 | 23 | 33 | 0 | 0.607 | 0.607 | 0.689 |
| 0D | ours | 45 | 19 | 19 | 0 | 0 | 0 | 1.000 | 0.422 | 1.000 |
| 0D | undark | 45 | 19 | 1 | 10 | 18 | 56 | 0.053 | 0.022 | 0.091 |
| 0D | fqlite | 45 | 19 | 20 | 0 | 0 | 0 | 1.000 | 0.444 | 1.000 |
| 0D | bring2lite | 45 | 19 | 7 | 0 | 12 | 0 | 0.368 | 0.156 | 1.000 |
| 0D | sqlite_dissect | 45 | 19 | 18 | 3 | 2 | 0 | 0.895 | 0.400 | 0.857 |
| 0E | ours | 12 | 4 | 4 | 0 | 0 | 0 | 1.000 | 0.333 | 1.000 |
| 0E | undark | 12 | 4 | 3 | 6 | 1 | 27 | 0.750 | 0.250 | 0.333 |
| 0E | fqlite | 12 | 4 | 2 | 6 | 2 | 0 | 0.500 | 0.167 | 0.250 |
| 0E | bring2lite | 12 | 4 | 3 | 5 | 1 | 7 | 0.750 | 0.250 | 0.375 |
| 0E | sqlite_dissect | 12 | 4 | 3 | 633 | 1 | 7 | 0.750 | 0.250 | 0.005 |
(Totals exclude 0C-06/0C-07; 0C therefore sums 8 databases, 84 deleted rows.
Regenerate with cargo test -p sqlite-forensic --test nemetz_tool_comparison --
--nocapture, with the tool gates set — UNDARK_BIN, FQLITE_TAP,
BRING2LITE_CMD, SQLITE_DISSECT_CMD. Each column is present only when its gate is set;
a bare run prints only the ours rows.)
Measurement provenance. All rows are measured in this repo against the same
Nemetz answer key and (col1,col2) matcher, regenerated by the harness with the
four oracle gates set. Two methodological notes:
0Cours precision 1.000 (0 phantoms), recall 70/84 is computed purely from our crate with no external tool: the structural-noise carve filter leaves no phantom in the cross-tool set.- fqlite is measured through our committed headless tap
(
tools/fqlite/tap/HeadlessTap.java), which emits every deleted row fqlite's engine reconstructs except non-record free-space carves (empty / whitespace / control-byte over-reads). Its recall is the engine's result (0C0.798,0D1.000,0E0.500); its precision reflects that tap's emission policy, so weigh the recall.
The bring2lite and sqlite_dissect rows are measured by us in this repo
against the same answer key and the same (col1,col2) matcher (BRING2LITE_CMD =
scripts/run-bring2lite.sh, SQLITE_DISSECT_CMD = scripts/run-sqlite-dissect.sh;
provenance in corpus-catalog.md §F).
- bring2lite carves a real but smaller slice of the deleted set: it reaches
40/84 of the
0Cfree-block rows at precision 1.000 (no phantom, no live re-read), trailing our 70 and fqlite's 67. On0Eits text rows decode through a Python-bytesfallback that does not byte-match the answer key, so it shows 5 phantom FP and re-surfaces 7 live rows as deleted (precision 0.375) — a precision behaviour our carver and fqlite do not exhibit. - sqlite_dissect (DC3) is a capable carver with a high phantom cost. With
carving enabled (
-c -f), DC3's SQLite Dissect recovers real deleted rows — 51 of 84 on0C(recall 0.607, precision 0.689) and 18 of 19 on0D(0.895/0.857) — but on0Eits freelist/overflow carving (its own help marks freelist carving "under development") emits 633 phantoms and re-surfaces 7 live rows as deleted (precision 0.005), the false-positive hazard our structural exclusion rules out. Measured viascripts/run-sqlite-dissect.sh(SQLITE_DISSECT_CMD).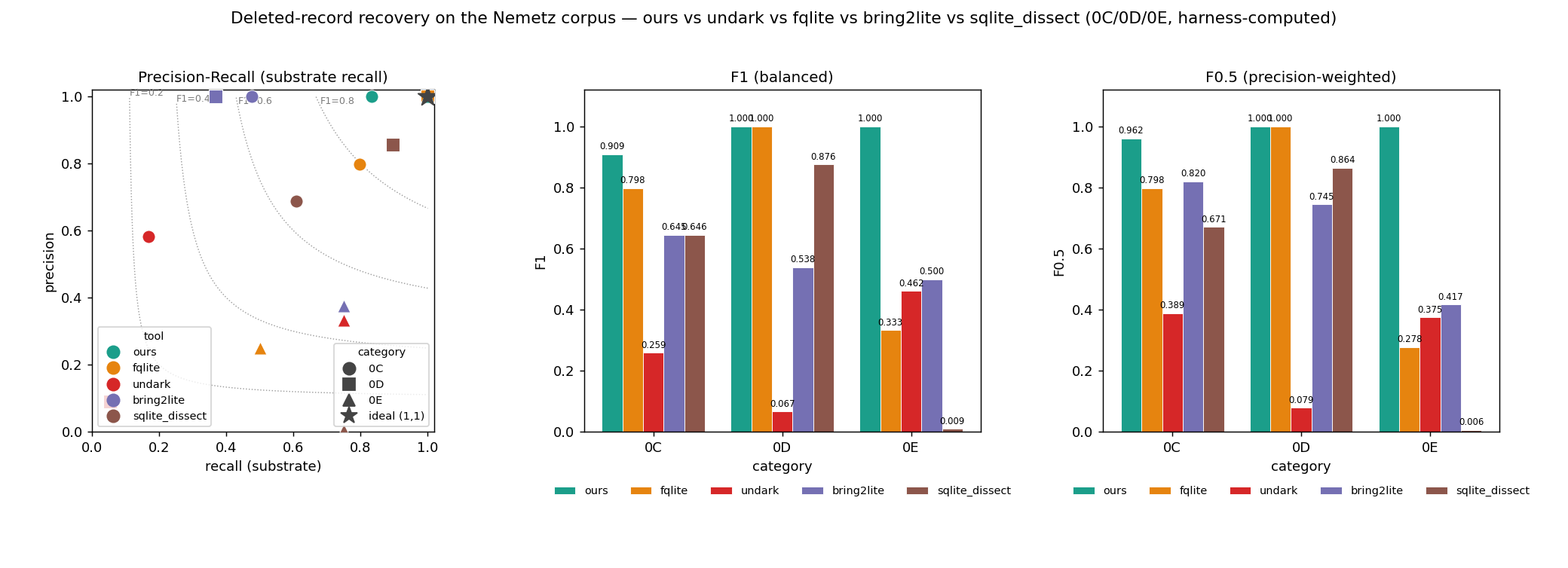
The figure plots the same harness-computed numbers as the table above:
forensic/tests/nemetz_tool_comparison.rs writes the per-(tool, category)
recall_substrate, precision, F1, and F0.5 to
img/comparison_metrics.csv when run with the
undark/fqlite oracles, and docs/plot_comparison.py renders the chart straight
from that CSV — chart and table are the same dataset by construction. By F1
(balanced), sqlite-forensic leads 0C (0.909 vs fqlite 0.798); under F0.5
(precision-weighted — the forensic β, since a phantom row costs an examiner more
than a missed low-confidence one) the 0C lead widens (0.962 vs fqlite 0.798). The 0E
F-scores are computed on the 4-row substrate (3 in-page contiguous + 1 followable
chain); ours recovers all 4 at precision 1.000, but with end-to-end 0E recall at
0.333 that remains a limited capability — most deleted overflow bodies were
overwritten. On 0D, ours and fqlite both
score 1.000 on substrate
recall, precision, and therefore both F-scores — each recovers every row whose full
identity survives. To refresh: rerun the test with UNDARK_BIN/FQLITE_TAP set to
rewrite the CSV, then python3 docs/plot_comparison.py to rerender the PNG. (The
committed CSV/PNG were produced by that oracle run; FQLITE_TAP =
tools/fqlite/run-tap.sh, UNDARK_BIN = tools/undark.)
Honest read — who wins where, and why¶
- In-page deletion (
0C): ours leads on both recall and precision; undark trails. With freeblock reconstruction our recall reached 0.833 (70 of 84), ahead of fqlite's 0.798 (67) — and at precision 1.000 (0 phantoms) versus fqlite's 0.798 (17 phantoms). We re-read no live row. - Deleted-then-overwritten (
0D): ours and fqlite both recover every row whose identity survives — substrate recall 1.000, precision 1.000; undark fails on precision. undark re-surfaces 56 live rows as deleted here (precision 0.091) — it mis-parses these overwritten tables and re-reads the live cells. Against the honest contiguous full-row-identity denominator (19 of the 45 deleted rows still carry a survivable scored identity; the rest were destroyed by later same-rowid overwrites), our span-walk reconstruction recovers all 19, matching fqlite — both at precision 1.000, both with 0 live-re-reads. (fqlite projects 20 TPs under the cross-tool(col1,col2)projection against the denominator of 19 substrate-recoverable rows; that extra projected row is not part of the recoverable substrate.) - Overflow (
0E): partial chain recovery, a limited capability. End-to-end0Erecall is 0.333 — most deleted overflow rows were overwritten and cannot be recovered by any carver. Against the honest denominator (3 in-page contiguous rows + 1 chain that survives through freelist leaves) our carver recovers all 4 with no false positive, including the one reassembled overflow chain (Ella); the destroyed chain (Matteo, page-5 trunk) is correctly excluded and degrades to a Tier-2 fragment. undark recovers 3/4 on the substrate but re-reads 27 live rows (precision 0.333); fqlite recovers 2 deleted overflow rows end-to-end, 2 within the 4-row substrate (substrate recall 0.500, precision 0.500).
The consistent picture (per the committed oracle run): our carver leads fqlite
on in-page recall (0C, 0.833 vs 0.798) while holding precision 1.000 on every
category (no phantom, no live re-read); it matches fqlite on
overwritten records (0D) — both recover every row whose full identity survives, at
precision 1.000. On the 0E overflow substrate (4 rows) ours recovers 4/4 to
fqlite's 2/4, but end-to-end 0E recall (0.333) keeps overflow a limited
capability, not a headline claim; undark trails on precision throughout and over-reports live rows as
deleted.
Live sqlite_master re-reads — a precision artifact, measured per tool¶
A subtler precision failure than a phantom row is re-surfacing the database's
current sqlite_master schema row — the live page-1
(type, name, tbl_name, rootpage, sql) table-definition record — as if it were a
recovered deleted record. It was never deleted, so reporting it as recovered
mis-presents a live object as evidence. This is distinct from the user-row
live-re-read in the matrix above (which counts a carved row equal to a live
user-table row): the schema row is not a user-table row, so it never enters
that alive set and a separate measurement is needed.
The detector is general, derived from the schema itself (not a per-database
constant): a recovered record counts as a live schema re-read iff its
(type, name, tbl_name) identity equals a row returned by the live page-1 schema
read. Measured across the in-scope corpus (the same 18 databases the head-to-head
scores — 0C/0D/0E minus the two FLOAT-key exclusions):
| tool | live sqlite_master re-reads |
|---|---|
| ours | 0 |
| undark | 0 |
| fqlite | 25 |
fqlite emits the live schema-table row as a recovered record on every
in-scope database (one per single-table DB, two per two-table DB). Our carver
emits 0 — the live schema rows are folded into the same value-based live-row
filter that suppresses re-reads of live user rows, so the schema record is
recognised as live and dropped. undark emits 0 because it does not
reconstruct sqlite_master at all (it surfaces only raw cell rows). The count is
reproducible from forensic/tests/nemetz_tool_comparison.rs
(live_sqlite_master_rereads_per_tool) with UNDARK_BIN and FQLITE_TAP set.
How the matrix is computed¶
For each database, the carver's output is matched against the answer key by full decoded-row content (schema column order; integers in decimal, reals at 5 decimal places, text verbatim, NULL as empty — the corpus's export format, applied symmetrically to both sides):
- TP — a carved row equal to an answer-key deleted row.
- FP — a carved row equal to neither a deleted nor a live row (a phantom).
- live-re-read — a carved row equal to a live row; counted separately, never folded into FP, so the two very different failure modes stay distinct.
- FN — an answer-key deleted (substrate-recoverable) row no carved row matched.
Recall is reported with two denominators:
- substrate-limited recall = TP /
|D_recoverable|— of the deleted rows whose scored identity physically survives in the file (a corpus property computed independently of our carver: the full record body surviving contiguously, decided per record by body size; a record that genuinely overflows onto an overflow-page chain counts when its chain is followable through freelist leaves to a byte-exact reassembly), how many did we recover? The carver-capability number. - end-to-end recall = TP /
|D_deleted|— of all rows the workload deleted (some destroyed by later overwrites), how many did we recover? The examiner-usefulness number.
F2 is F-beta with β = 2 (recall-weighted, since missing evidence costs an
examiner more than discarding a low-confidence phantom), over precision and
substrate-limited recall.
The Tier-2 fragment surface (see "Two-tier recovery") is measured with its own counts, never blended into the full-row matrix above:
- fragment-recoverable = the denominator: deleted rows whose full identity is destroyed (not substrate-recoverable) yet at least one distinctive cell — TEXT of ≥ 4 UTF-8 bytes, or REAL — still survives contiguously somewhere in the file. Bare integers are excluded (a 1–8-byte integer pattern coincides too often to anchor identity), so numerator and denominator share one distinctiveness rule.
- fragment-TP = a salvaged fragment whose surviving distinctive cells equal the corresponding columns of an answer-key deleted row.
- fragment-FP = a fragment matching neither a deleted nor a live row (phantom) or matching a live row (live-re-read). Measured and reported separately, because the fragment surface — unlike the full-row tier — has an expected non-zero false-positive rate; that is precisely why it is opt-in.
Our carver — per-database detail (computed)¶
The head-to-head above totals each tool per category. This section breaks our
carver down per database (from nemetz_metrics.rs), so a low category recall
can be traced to specific files. It differs from the head-to-head in two
deliberate ways, both of which slightly raise the count reported here versus the
head-to-head's ours row: it matches on the full decoded row (all columns,
reals at 5 dp) rather than the (col1,col2) projection, and it includes
0C-06/0C-07 (whose float key columns the cross-tool table must drop). So our
0C total here is 87 (over all ten 0C databases) versus 70 in the head-to-head
(eight databases) — the same carver, two compatible scopings.
Categories: 0C deleted records (in-page free block); 0D deleted then
overwritten; 0E deleted overflow records. Ddel = rows deleted; Drec = of
those, the recoverable substrate — rows whose full scored identity survives
contiguously (or, for an overflow row, whose chain is followable through freelist
leaves to a byte-exact reassembly), decided per record by body size; live =
live-re-reads (must be 0).
| DB | Ddel | Drec | TP | FP | FN | live | recall (substrate) | recall (e2e) | precision | F2 |
|---|---|---|---|---|---|---|---|---|---|---|
| 0C-01 | 7 | 7 | 7 | 0 | 0 | 0 | 1.000 | 1.000 | 1.000 | 1.000 |
| 0C-02 | 10 | 10 | 10 | 0 | 0 | 0 | 1.000 | 1.000 | 1.000 | 1.000 |
| 0C-03 | 7 | 7 | 7 | 1 | 0 | 0 | 1.000 | 1.000 | 0.875 | 0.972 |
| 0C-04 | 10 | 10 | 10 | 2 | 0 | 0 | 1.000 | 1.000 | 0.833 | 0.962 |
| 0C-05 | 10 | 10 | 10 | 0 | 0 | 0 | 1.000 | 1.000 | 1.000 | 1.000 |
| 0C-06 | 7 | 7 | 7 | 0 | 0 | 0 | 1.000 | 1.000 | 1.000 | 1.000 |
| 0C-07 | 10 | 10 | 10 | 0 | 0 | 0 | 1.000 | 1.000 | 1.000 | 1.000 |
| 0C-08 | 10 | 10 | 10 | 1 | 0 | 0 | 1.000 | 1.000 | 0.909 | 0.980 |
| 0C-09 | 10 | 10 | 5 | 0 | 5 | 0 | 0.500 | 0.500 | 1.000 | 0.556 |
| 0C-10 | 20 | 20 | 11 | 0 | 9 | 0 | 0.550 | 0.550 | 1.000 | 0.604 |
| 0C total | 101 | 101 | 87 | 4 | 14 | 0 | 0.861 | 0.861 | 0.956 | — |
| 0D-01 | 5 | 1 | 1 | 0 | 0 | 0 | 1.000 | 0.200 | 1.000 | 1.000 |
| 0D-02 | 5 | 1 | 1 | 0 | 0 | 0 | 1.000 | 0.200 | 1.000 | 1.000 |
| 0D-03 | 5 | 0 | 0 | 0 | 0 | 0 | 1.000 | 0.000 | 1.000 | 1.000 |
| 0D-04 | 5 | 2 | 2 | 0 | 0 | 0 | 1.000 | 0.400 | 1.000 | 1.000 |
| 0D-05 | 5 | 0 | 0 | 0 | 0 | 0 | 1.000 | 0.000 | 1.000 | 1.000 |
| 0D-06 | 10 | 5 | 5 | 0 | 0 | 0 | 1.000 | 0.500 | 1.000 | 1.000 |
| 0D-07 | 5 | 5 | 5 | 0 | 0 | 0 | 1.000 | 1.000 | 1.000 | 1.000 |
| 0D-08 | 5 | 5 | 5 | 0 | 0 | 0 | 1.000 | 1.000 | 1.000 | 1.000 |
| 0E-01 | 7 | 4 | 4 | 0 | 0 | 0 | 1.000 | 0.571 | 1.000 | 1.000 |
| 0E-02 | 5 | 0 | 0 | 0 | 0 | 0 | 1.000 | 0.000 | 1.000 | 1.000 |
(Dropped/overwritten-table categories 0A/0B carry no row-level deleted set
that anchors a live-vs-deleted distinction — the whole table is gone — so they are
reported as bounded dropped-table recovery, not in the recall matrix; their
correctness is measured by the DC3 differential below.)
Reading the numbers¶
- 0C precision 0.956 (87 TP / 91 carved): the only leaks are the phantom all-empty class (4 across 0C-03/04/08), never a live row. Freeblock reconstruction added the freeblock-head cells without adding a single live-re-read.
- 0C recall ≈ 86 % with every deleted row substrate-present: reconstruction recovers the freeblock-head cells the forward parser missed; the residual FN are 0C-09/0C-10 (whose freed cells have no freeblock chain — they sit in the unallocated gap with a destroyed prefix the template cannot anchor).
- 0D substrate recall 1.000 (19 TP / 19 Drec): span-walking freeblock
reconstruction recovers every coalesced cell in a free span, not just the
span's head — and the substrate denominator is now the honest contiguous
full-row-identity count, so it equals exactly the rows whose scored identity
still survives. The carver recovers all of them. End-to-end recall (TP / Ddel)
stays lower because later
INSERTs genuinely destroyed ~26 of the 45 deleted rows' identities. - 0E substrate recall 1.000 (4 TP / 4 Drec): most
0Edeleted bodies are large-but-in-page and survive contiguously, and the carver recovers all of them. The honest denominator is 4 — 3 in-page contiguous rows plus 1 overflow chain (Ella) that is followable through freelist leaves to a byte-exact reassembly. The other overflow chain (Matteo, page-5 trunk) was overwritten and is excluded (it degrades to a Tier-2 fragment). Overflow Tier-1 is a graded recovery, not part of the structural 0-false-positive guarantee: a freelist leaf can be stale, so the chain-reassembled row is graded below the in-page full-row tier.
Freeblock reconstruction¶
This was the dominant FN class before freeblock-aware reconstruction, and the fix that closed it.
When SQLite frees a cell from an allocated page, it converts the cell into a
freeblock (file-format §1.6): the first two bytes become the next-freeblock
pointer and the next two the freeblock size — overwriting the cell's first four
bytes, which span the payload-length varint, the rowid varint, the record
header_len varint, and the leading serial type(s). The record's surviving
serial-type tail and its whole value body remain intact after those four
bytes.
Database::reconstruct_freeblock_records rebuilds each freed cell from that
surviving tail plus a schema template derived from a live cell on the same
page — the table's column count, header length, and the serial types of the
leading columns that fall inside the clobbered prefix (e.g. a fixed-width id
column). It walks the page's freeblock chain (bounded, cycle-safe), reads the
surviving serials at the byte offset where the clobber ends, prepends the
template's leading serials, and decodes the body. The destroyed rowid is surfaced
as unknown (0) — never invented — and the record is graded LOW
(FREEBLOCK_RECONSTRUCT_CONFIDENCE), tagged RecoverySource::FreeblockReconstructed.
Precision is preserved by construction. A reconstructed candidate is emitted
only when every serial type is legal AND the whole record fits within the
freeblock's [offset, offset + size) bounds; the forensic layer additionally
drops any reconstruction whose decoded values match a live row (by value, since
the rowid is gone). The result: 0C recall 0.274 → 0.833 with 0 new phantoms and
0 live-re-reads — above fqlite's recall at higher precision (0 phantoms vs 17).
This is the published forensic technique (Nemetz et al. 2018; Pawlaszczyk & Hummert 2021), implemented from the SQLite file-format spec — not adapted from any GPL tool's source.
Two-tier recovery — Tier-2 fragments¶
Recovery is split into two strictly separated tiers:
- Tier 1 — full rows (the matrix above):
carve_all_deleted_recordsrebuilds complete, scored identities and keeps the structural 0-false-positive guarantee. Always present in the carve output. - Tier 2 — fragments (shown by default;
carve --no-fragmentsto suppress): where a freed cell's full row cannot be reconstructed but a distinctive cell survives at the same structural anchor, the maximal decodable column prefix is salvaged as aCarvedFragment— a separate type with no rowid and an incomplete column set, rendered in its own section so it can never be mistaken for a recovered row.
The honest read of the deleted-then-overwritten category 0D is three buckets:
| of 45 deleted 0D rows | count | meaning |
|---|---|---|
| fully reconstructable | 19 | full identity survives; all recovered (Tier-1 substrate recall 1.000) |
| yield a genuine fragment | 5 | full identity destroyed, but a distinctive TEXT cell survives |
| destroyed / undecidable | 21 | nothing distinctive survives a later overwrite |
Of the 5 fragment-recoverable 0D rows, the on-disk freeblock/gap extractor reaches
1 (0D-01, id 20004: name='Anja' surname='Frank', the codeB REAL tail
clobbered). The other 4 survive only inside live-cell extents the carver must
never scan (re-surfacing them would break the never-touch-a-live-row guarantee)
or at offsets no freeblock/gap anchor walks — so fragment recall < 1.0 is expected
and honest, not a defect. 0E has 3 fragment-recoverable rows (long TEXT split
across overflow pages); the broken-chain overflow fragment salvage reaches one of
them — Matteo (chain page 5 the freelist trunk), whose intact local prefix yields
id and name after the chain is rejected from Tier-1. 0C is fully
reconstructable, so it yields no fragments.
Filtering recovered items by confidence¶
Every carved record and fragment carries a confidence set by its recovery path
(the _confidence column / confidence JSON field). The distinct values:
| confidence | recovery path |
|---|---|
| 0.9 | full row with distinctive UTF-8 TEXT — a freed cell, dropped-table page, or live / prior-version row |
| 0.72 | full row rebuilt in-page from a free block, distinctive text (0.9 × 0.8) |
| 0.675 | full row whose body spilled to an overflow chain (0.9 × 0.75) |
| 0.6 | full row, no distinctive text |
| 0.48 | in-page free-block row, no distinctive text (0.6 × 0.8) |
| 0.4 | row reconstructed from an exact-tiled free block |
| 0.30 | exact-tiled free-block row that spilled to overflow (0.4 × 0.75) |
| 0.2 | Tier-2 fragment |
--min-confidence keeps only items at or above a level — info 0.0 · low 0.2 ·
medium 0.4 · high 0.6 · critical 0.8 — partitioning the output:
| level | keeps |
|---|---|
info (default), low |
all of the above |
medium |
drops Tier-2 fragments (0.2) and overflow free-block rows (0.30) |
high |
also drops free-block reconstructions (0.4) and text-poor in-page rows (0.48) |
critical |
only distinctive-text full rows (0.9) — drops in-page (0.72) and overflow-spill (0.675) too |
The dial applies to every emitted item, full records and fragments alike;
--fragments forces the fragment surface in past the threshold and --no-fragments
removes it. info and low are equivalent under the current confidence set (no
item scores in [0.0, 0.2)); both are kept so the ladder mirrors the standard
severity scale and stays correct if a future recovery path lands a value between
them.
Because a lone surviving cell can be a coincidental byte run that satisfies the serial + UTF-8 checks, the fragment surface carries an expected non-zero false-positive rate and is therefore opt-in — the full-row tier's 0-false-positive claim is never extended to it. On this corpus the measured fragment false positive count is 0 (every emitted fragment matched a real deleted row, none a live row), but the mechanism permits more, which is why the default output never includes fragments.
| category | deleted | full-recoverable | fragment-recoverable | fragment-TP (extractor) | fragment-FP |
|---|---|---|---|---|---|
| 0C | 101 | 101 | 0 | 0 | 0 |
| 0D | 45 | 19 | 5 | 1 | 0 |
| 0E | 12 | 3 | 4 | 0 | 0 |
(A 0D row counts as fragment-recoverable only when a genuinely distinctive cell
survives — a TEXT ≥ 4 UTF-8 bytes or a REAL. Bare 1–4-byte integers are
excluded: they match coincidental byte runs across a page, so they are not
evidence a row survived. On 0D the distinctive-cell denominator is 5.)
fqlite and undark have no comparable fragment tier, so the head-to-head matrix stays full-row-only (apples-to-apples); fragments are an ours-only capability reported here.
What the numbers do and do NOT claim¶
- They claim an honest, reproducible measurement of all five tools against
this independent corpus (per the committed oracle run): our carver leads fqlite
on in-page recall (
0C) at precision 1.000 and never re-reads a live row; it matches fqlite on overwritten records (0D), where both recover every row whose full identity survives; on the0Eoverflow substrate ours recovers 4/4 to fqlite's 2/4, though end-to-end0Erecall (0.333) keeps overflow a limited capability; undark trails on precision and over-reports live rows as deleted on the overwritten and overflow tables. - They do not claim our carver is "best" overall. On
0Dend-to-end, fqlite's cross-tool(col1,col2)projection counts 20 TPs to our 19 (against a denominator of 19 substrate-recoverable rows); on0Cwe lead fqlite by raw recall; on0Eend-to-end recovery is limited for both (ours 0.333, fqlite 0.167) — not a meaningful lead. We hold a structural 0-false-positive guarantee on the in-page tier and zero phantoms throughout; overflow Tier-1 is a separate graded path (a freelist leaf can be stale), not part of that structural guarantee. - A low per-category end-to-end recall is a true statement about a capability boundary, not a harness artifact — the two-denominator split separates "the bytes did not survive" (substrate) from "the bytes survived and we missed them" (carver capability).
Inter-tool concordance on our own fixture (agreement, not correctness)¶
Separate from the head-to-head above (which scores each tool against ground
truth), oracle_differential.rs reconciles our output against undark and fqlite
as oracles over our own deleted_places.db fixture — it answers "do we agree
with them?", not "how does each score?". On that fixture (whole-freed-page
deletion — the shape our carver handles), our output matches undark exactly
(163 rows) and matches-or-exceeds fqlite, and on the prior-version fixture we
match fqlite and exceed undark. This is genuine agreement on that deletion
shape, but it is inter-tool concordance, not ground truth — which is why the
Nemetz head-to-head (real answer keys) is the headline.
DC3 sqlite_dissect corpus — a no-false-positive regression set¶
The DC3 corpus carries no deleted-row ground truth: its expected_rows were
found (independently confirmed: freelist_count = 0, contiguous rowids,
expected == SELECT * on the readable DBs) to be the live table content, used
upstream only as a precision allow-list. We therefore keep it solely as a
no-false-positive / NoGenuineDeletion regression set (the carver must not
re-surface those intact live rows) plus a dropped-table recovery check on
0A-01/0A-02. No precision/recall is computed from it.
WAL-resident records¶
Out of scope for the carver: a row that exists only in an uncheckpointed -wal
overlay is live (not yet checkpointed), not deleted, so it is not a carving
target. sqlite-core surfaces the WAL-applied view via
Database::open_with_wal, and the auditor flags an active overlay as
WalUncheckpointedState. Recovering genuinely deleted content from within WAL
frames, with WAL-sequencing ground truth, is the subject of a separate
(NIST CFReDS-based) evaluation not yet landed.